Clean documentation
I spoke about this at Eurucamp 2012 in Berlin.
My goal here is not to give you a step by step guide to writing a readme. Instead, I want give you a few ideas to think about the next time you consider writing documentation or actually end up doing it.

What do I mean when I say Clean Docs? There’s an explanation of clean code in Uncle Bob’s Clean Code book, but even if you haven’t read that, I’m sure you can tell the difference between code that’s clean and code that’s dirty. We have rules in our heads about that and alarm bells go off when we start writing code that’s dirty and going to cost us later on. I want to encourage you to develop that same kind of awareness and discipline for when you’re writing documentation.

One of the Agile principles states: ‘We have come to value working software over comprehensive documentation’. When you read that it’s easy to get a feeling of relief and think ‘okay, great! I don’t have to worry about documentation. I’m just going to make software that works.’ But of course that’s not quite what it’s saying. It’s actually saying that comprehensive documentation has value, but that working software has more. I agree. However, I believe this is referring largly to project documentation - things like requirements documents and design plans - and that’s not what I’m talking about here. Also, working software is good but I suggest we aim even higher and create usable software. Documentation can help you achieve that.

There are many kinds of documentation. One way to break them down is by proximity to code. We can start with the actual code itself, which can serve as a form of documentation if it is clear enough, and move through technical documentation, project websites and general documentation, all the way to published books. What I have to say about Clean Docs applies to the forms of documentation that are closer to the code. The readme is right in the middle of that range but the rest is relevan as well.

It has been said that ‘good code is its own best documentation’. That’s very true in a sense, but unfortunately it’s become the biggest excuse for developers to completely ignore documentation. Without digging too deep - just by rereading that statement - we can see that code being its own best documentation is dependent on the code being good. Beyond that immediate observation I would add that the relevance of code as documentation depends on what the user is trying to get out of it. Even the best code will have a hard time explaining the purpose and scope of your project in the first few seconds that a new user looks at it, but that’s easily acheivable in a couple of sentences of English.
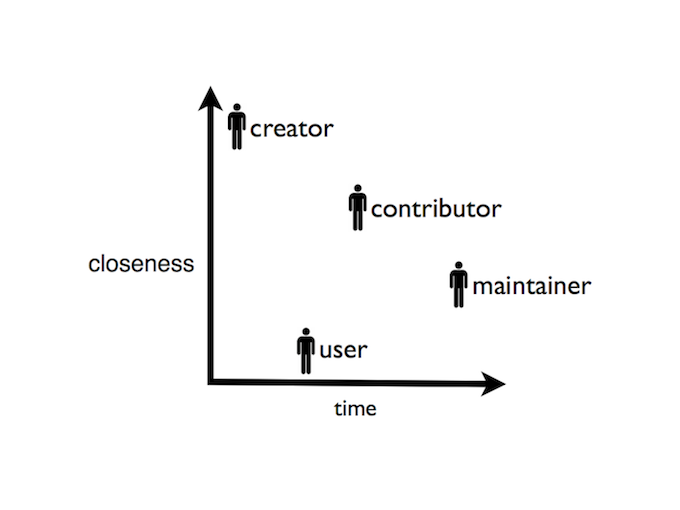
The users (including the maintainers) of your documentation will vary in their proximity to the code and their proximity to the present time. You should consider users across this whole plane when writing documentation. Writing more will help users unfamiliar with the code today, but require more work in maintenance later. Writing less will save on writing time, but may make it harder to maintain a clear scope, attract new users, and remember what the project is all about two years from now. Think about who your documentation is serving, and who is it costing, and when.

Without too much rewording, the principles of clean code listed above also all apply to documentation.

Take particular notice of the last point. A lot of people facing the prospect of writing documentation fear that it’s going to take a long time and it’s going to be difficult to maintain. The more you write, the more you really have to fear. So, minimise it.

You can minimise what you write by referencing things rather than reproducing them. For example, if your API documentation contains an explanation of some concept that readers of your readme will need in order to understand discussion there, just refer them to it, rather than reproducing the explanation in a second location.

What is brittle documentation? It’s the same a brittle code, it’s something that’s going to break as soon as you touch it.
For example, I had some code in which we had an API key. Let’s put aside the fact that it probably would have been better as configuration than as code. The immediate problem I had was that there had been confusion about whether this was a company key or a team key. I clarified that for myself and then I wanted to make it clear to future readers of the code.
I thought that I could use a more explicit variable name or alternatively I could put in a short comment that would document what the key was, but I realised that both of these solutions would be quite brittle. Someone would one day come along and change the API key. They probably wouldn’t update the comment and they almost certainly wouldn’t update a variable name.

A better solution was to come up with a form of documentation that would automatically expire if careless changes were made. In the last line above I’m saying that they key is cde0fc8a5c2b1ecc, and the key starting cde0 is the company key. That explains the situation to readers today and if the key is carelessly changed at some point, future readers will not be misled by the comment.
That code comment example is a small one, but the same principle can be used throughout your documentation. Try to write things that will tolerant of careless changes; that will make sense for as long as possible and that will be obviously irrelevant if things change in the future.

The first way to test your documentation is to test it against your code. Most of the time that just means cutting and pasting your code examples into IRB or another REPL and checking that you’ve got your syntax correct and that the examples run against the current version of your software. Sometimes it will be appropriate to automate that. If you’re writing a book, for example, you might write a script to pull lines of code out of executable files and insert them into your readable documentation. But manual checks are good enough most of the time.
You can also test against readers. A teammate will be able to read your writing and give you feedback, but the best person to check with is someone who doesn’t already know the information you’re trying to convey. Take a fresh person and see if they can understand you project by reading the documentation.
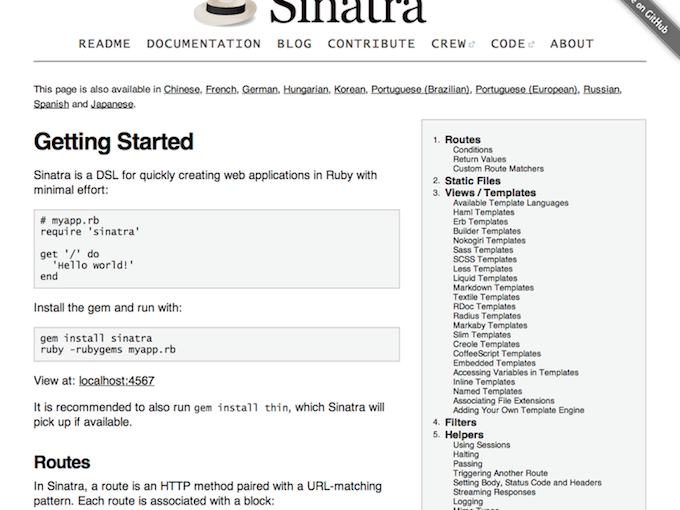
When we think about good documentation several examples come to mind. We’re generally pretty lucky in the Ruby world. The Sinatra readme is a fine example. Several people have told me they really love it and I know why. It’s well structured, it’s easy to read, it’s got appropriate code examples, you can easily search within the page, it links to external resources… it’s great! A lot of people use Sinatra, so it’s obvious that all of the effort that has been put into building up its comprehensive documentation is worthwhile.
But what about those projects that don’t seem worth documentation? Maybe it’s something that you hacked up on a weekend. You’re the only person who will ever use it and only a handful of other people might ever look at it. Even those projects deserve a readme.

There are some obvious things to put in: what it is, who you are and how to get started. To those I would add that you should be linking to whatever other things there are. If your project is at the point where there are additional resources that are relevant then link to them. In the example above I’ve linked to a blog post that explains what that demo app is.
Also consider adding a status section. That can be just one word, or up to a few sentences. It might just be something like ‘broken’ or ‘unmaintained’ or ‘in development’ but it could be a bit longer and say ‘this is a spike I did to learn X. It is retained only for reference.’ Having a status section helps new people looking at the project, but it also offers the benefit of taking unpolished code that’s not fit for public consumption and making it respectable, with just a few words. Also, it will make it easier for you to come back and pick up the project again if you decide to do something with it in the future.

The idea of readme driven development is that you write your readme before your code. That gives you an early chance to think about your software from the user’s perspective, and potentially, to discuss it. Of course, you continue to develop your readme and your other documentation as the implementation code grows.
Whether you write your readme before or after your code, you should definitely take the opportunity that documentation production and maintenance offers to re-examine your project; to refresh your view of how things fit together and what might come next.
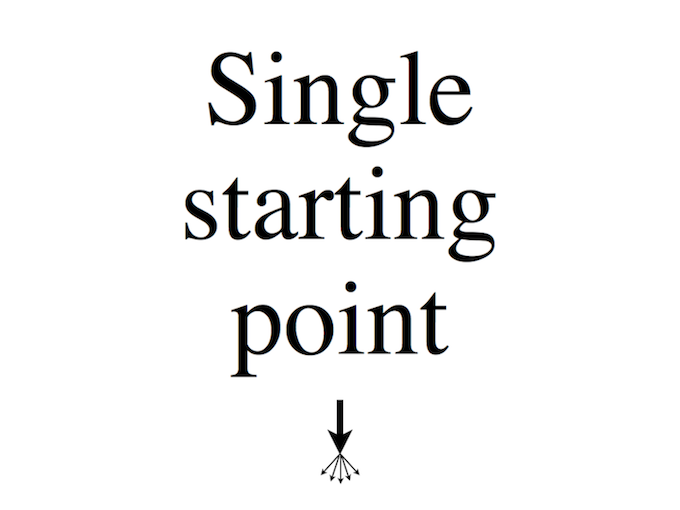
You documentation should have a single starting point. Usually it will be a readme, but sometimes it will something else, like a project website. Users should be able to start there and find everything that’s relevant to the project. Don’t make Google you starting point, because although it makes it easy to find individual resources, it’s not good at communicating how they fit together and what the status is, which is exactly what your documentation should be doing.

In summary: consider the needs of various readers and writers, both now and in the future. Have a single starting point for your documentation, link to everything from there, maintain that cohesive structure and use its maintenance as a chance to keep a fresh understanding of how things fit together. Cover the basics, usually in a readme and always as briefly as possible, and keep it clean, like you would your code.